
CoastSnap – Citizen Science for Coastal Observation
- Details
- Published: 01 July 2020 01 July 2020
By Roger Longhorn

CoastSnap is a global “Citizen Science” project devised to involve citizens in scientific research on the accretion and erosion of beaches. There are several methodologies using cameras and other remote sensing technologies to collect the needed information, but these typically require significant funding, ongoing maintenance, and technical knowledge. CoastSnap eliminates this by engaging the local community and tourists to capture the same images, using a simple installation comprising a holder for smartphones to ensure all pictures are taken from the same angle and position. The photos can be shared via social media (Twitter, Instagram, Facebook) or email, noting the date and time of the photo. All photo authors will remain anonymous.
The project provides specially designed smartphone holders at fixed “CoastSnap stations” where anyone can place their smartphones to take apicture of the beach from a known, fixed location and orientation. All of these photos will be collected into one large set, to be used by researchers to map the growth or erosion of target beaches.
CoastSnap is a global project, originated by Dr Mitchell Harley of the University of Sydney, where the first CoastSnap station was installed in 2017. Since then, several other countries have joined the CoastSnap network, with currently about 44 stations active across the globe, from Madagascar to Brazil, Spain, Belgium, the UK and the United States. An international platform is under development on which all these stations can be gathered. The representatives of the different stations try to meet annually to exchange ideas and experiences.
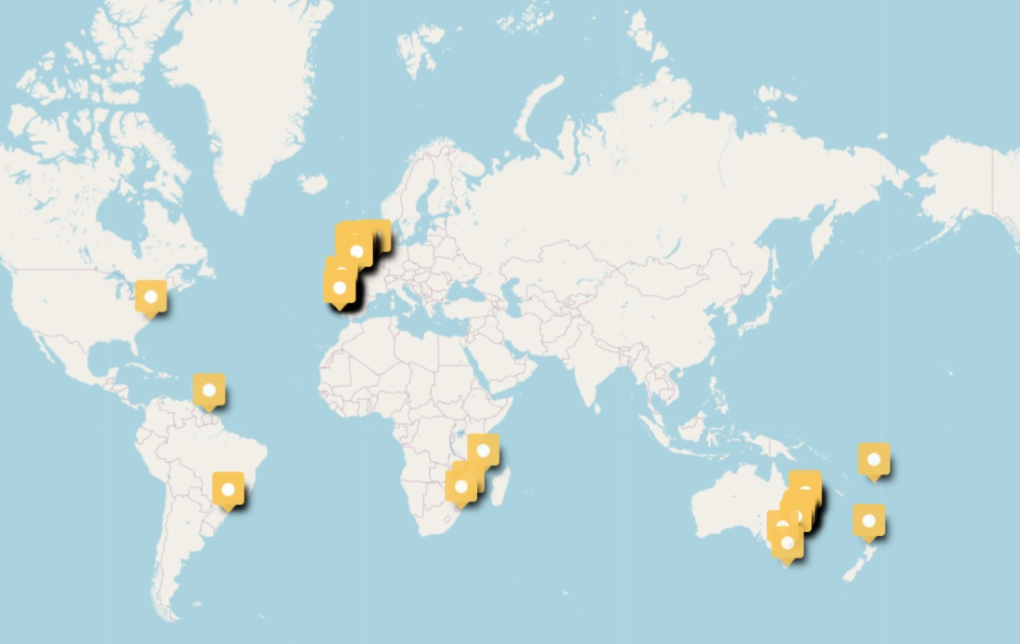
The first “CoastSnap station” in Belgium is in Ostend. This location is fitting to start the project in Belgium, being on a well visited tourist location that is also much frequented by local citizens throughout the year. The target beach on this location is subject to many factors that affect accretion, and CoastSnap can contribute to a better understanding of how exactly the beach responds to all those influences. A second station is planned for the coastal community of Koksijde. To learn more about CoastSnap in Belgium visit https://www.kustportaal.be/en/coastsnap-belgium.
To those ICAN members across the globe, consider joining the CoastSnap project.
For more information on CoastSnap progress, contact the CoastSnap Team at This email address is being protected from spambots. You need JavaScript enabled to view it. or visit their website at:
https://www.environment.nsw.gov.au/research-and-publications/your-research/citizen-science/digital-projects/coastsnap
SDG Goal 13
![]() SDG Goal 13: “Climate Action: Strengthen resilience and adaptive capacity to climate-related hazards and natural disasters in all countries.”
SDG Goal 13: “Climate Action: Strengthen resilience and adaptive capacity to climate-related hazards and natural disasters in all countries.”
Learn more about SDG 13 here

